
“I could not work like this” is what a professional translator might say, looking over the shoulder of a colleague typing SAP translations into a Microsoft Excel spreadsheet. What’s wrong with this, her colleague might ask. “You’re not using a translation memory”, might be her first answer, and she might also point to the Proposal Pool, SAP’s translation memory variant. This is part one of a two-part series, you can read part two here.
The Age of the Translation Memory
Translation memory systems were first widely used in the 1990s, as a tool to make translation more efficient and improve consistency. A translation memory is a repository that stores text pairs that consist of source text, target text, and often some metadata. For each translation a translator enters for a document, this translation will also be stored in the translation memory. When this translator, or another translator working with the same translation memory, then encounters a text that is identical or similar to a source text stored in the translation memory, their translation tool will propose the existing translation, and let the translator easily reuse it.

This technology has been the bedrock of the translation industry for more than 25 years, and is probably the biggest source of translation costs saved. Today, very few translators work on anything without using a translation memory. It’s hard to overstate how ubiquitous these systems are.
The Curious Case of the Proposal Pool
SAP has translated its software into many languages, and has done so for more than 40 years. So it comes as no surprise that they needed a translation memory solution that worked for translating user interface texts in SAP systems. What they came up with was a translation memory system that is uniquely adapted to user interface translation, and to SAP translation in particular. Although fairly unknown in the wider translation industry, the proposal pool, which is now more than 20 years old, is one of the best of its kind and if you ask me, is one of the best things about SAP translation, period.
The design of the proposal pool aggressively promotes translation quality over reusing texts at any cost and whether they fit the context or not. It is also very much part of the fabric which makes up transaction SE63 and the larger translation environment in an ABAP-stack SAP system. And while some of its underlying ideas and design decision seem obvious in hindsight, others seem baffling at first. One of the less obvious choices is the reliance on exact matching over fuzzy matching.
Exact Is Better
It is quite possible that the absence of fuzzy matching was not part of a grand design, but that exact matching simply was easier to implement. The fact is, when a translator now translates a user interface text like Assets from English into German, the proposal pool will surface matches for Assets (such as Anlagen in German), but not for Asset, the singular. This looks like a drawback initially, because that translator may miss the fact that while Assets has not been translated before, for Asset, a translation may be available that the translator may want to refer to. (You can search the proposal pool using placeholders, mind you, but during translation, only exact matches will be proposed.)
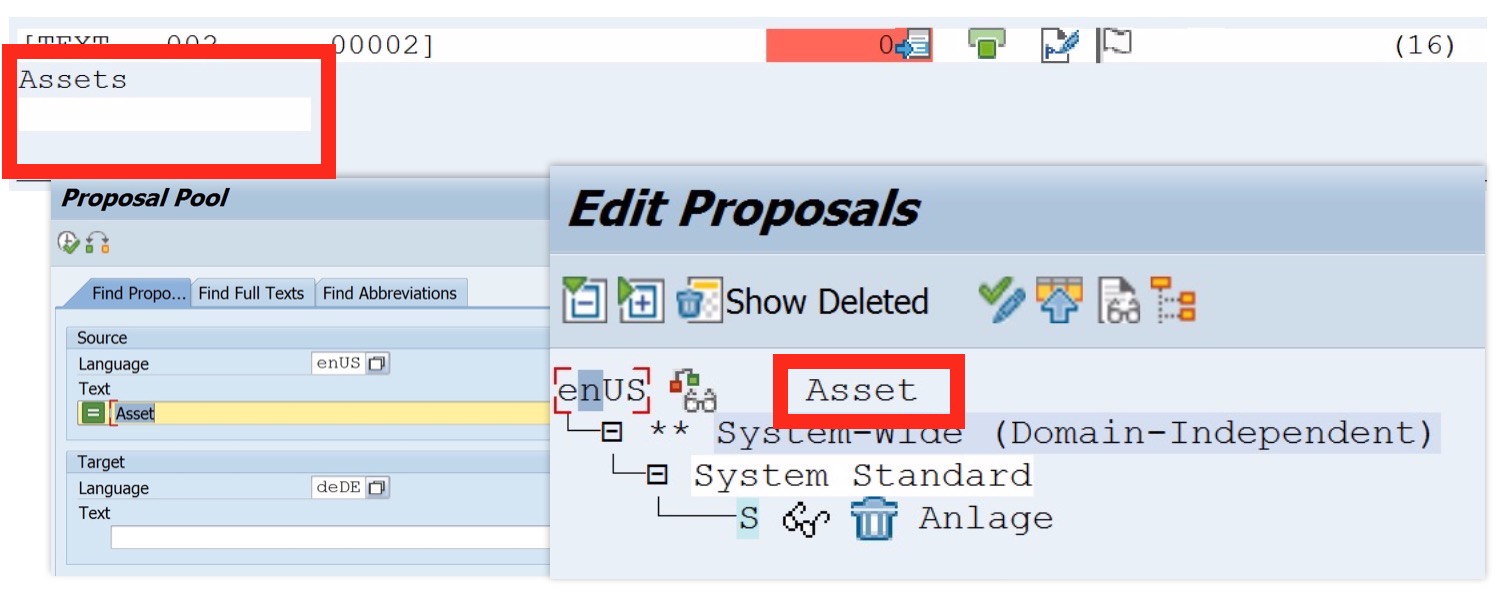
For longer texts like error messages or documentation-style texts, this is a real drawback. But for the very short texts that make up the majority of SAP user interface texts, or any other software texts, it’s in fact an advantage. Proposing only exact matches makes it more likely that the translation surfaced is actually a good match for a source text, which means a translator can make the decision whether to use a proposal or to enter a different translation much quicker, and decide with more confidence.
But more importantly, this design around exact matching allows for a number of automation and quality improvement features. These features may not be used much by translators , but project managers, language technologists and consultants rely on them in ways that no other translation memory system allows.
All Proposals Are Not Created Equal
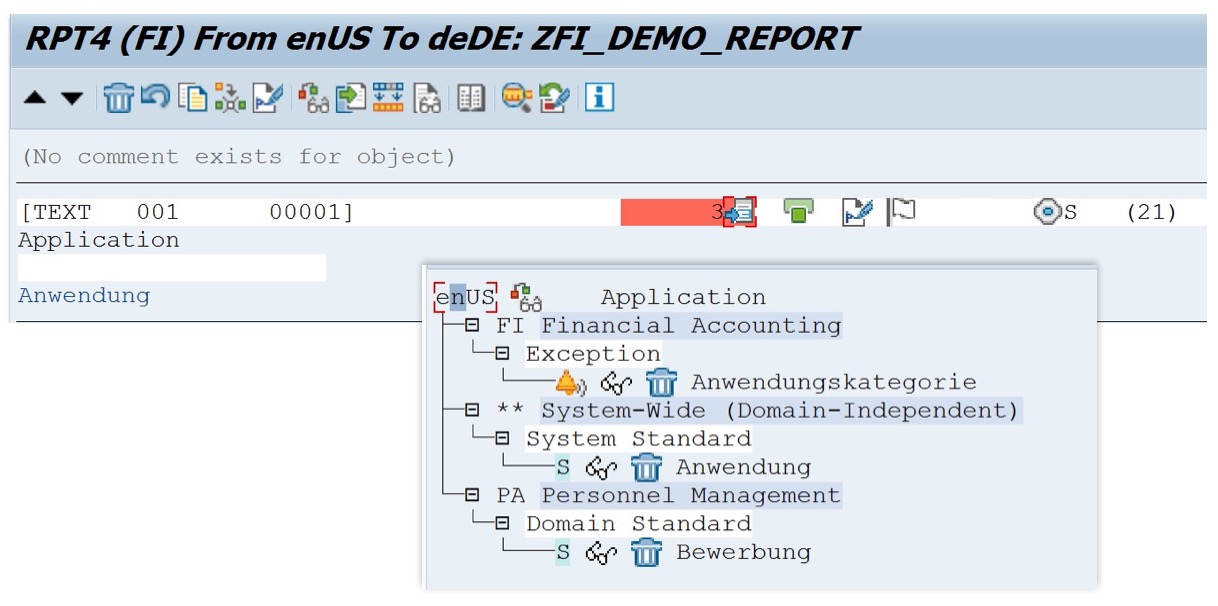
Another core feature of the Proposal Pool is a little more obvious: Translators can create proposals for specific terminology domains, and they can create so-called exceptions. Domain-specific proposals come in very handy when a text needs to be translated differently depending on the context. A text like Application may refer to a computer application or program in most contexts, but in a human resources context, it most often refers to a job application and needs to be translated accordingly. A German translator can therefore create the proposal Bewerbung for the HR terminology domain. For texts associated with other terminology domains, this proposal will then never be surfaced.
Exceptions are another way that proposals can be hidden away from translators in contexts where they are not relevant. When a translator has to translate a text in a very non-obvious way, using a translation that will be incorrect in basically any other case, they can create a proposal of the type Exception. These are just two ways the proposal pool is designed to propose the highest quality proposal to the translator at the time of translation, and make sure proposals that do not fit the context are not used.
Strong Fundamentals
These are some of the features that make the Proposal Pool so different from the translation memory systems used by translation industry staples such as SDL Trados Studio and Memsource. If you abstract away from the admittedly somewhat outdated user interface of SE63’s short texts editor where the Proposal Pool is mainly used and take a step back, you can see that its design really is quite modern. In fact, many of the reasons that still make SE63 one of the most efficient editing environments for SAP translations go back to the Proposal Pool.
Learn more about our SAP translation consulting services…